한 줄 요약같은 작업을 GPT-5.5로 돌리면 $30, DeepSeek V4-Pro로 돌리면 $3.48이에요. 출력 토큰 기준 9배 차이. 그런데도 많은 빌더가 그 중간 어딘가에서 가장 비효율적인 모델에 매달 돈을 태우고 있어요. 가운데 가격대가 무너진 지금, 답은 하나로 정해졌어요. 라우팅.
매달 LLM API 청구서를 보고 "이게 맞나?" 싶었던 적 있죠. 한 가지만 짚을게요. 당신이 지금 쓰는 모델이 GPT-5.4, Sonnet 4 같은 '미들 티어'라면, 2026년 봄부터 그건 가장 손해 보는 선택지가 됐어요. 비싸지도 싸지도, 가장 똑똑하지도 가장 효율적이지도 않은 어중간한 칸. 시장이 그 칸을 통째로 비우는 중이거든요.
가격표 한 장이 시장 구조를 바꿨어요
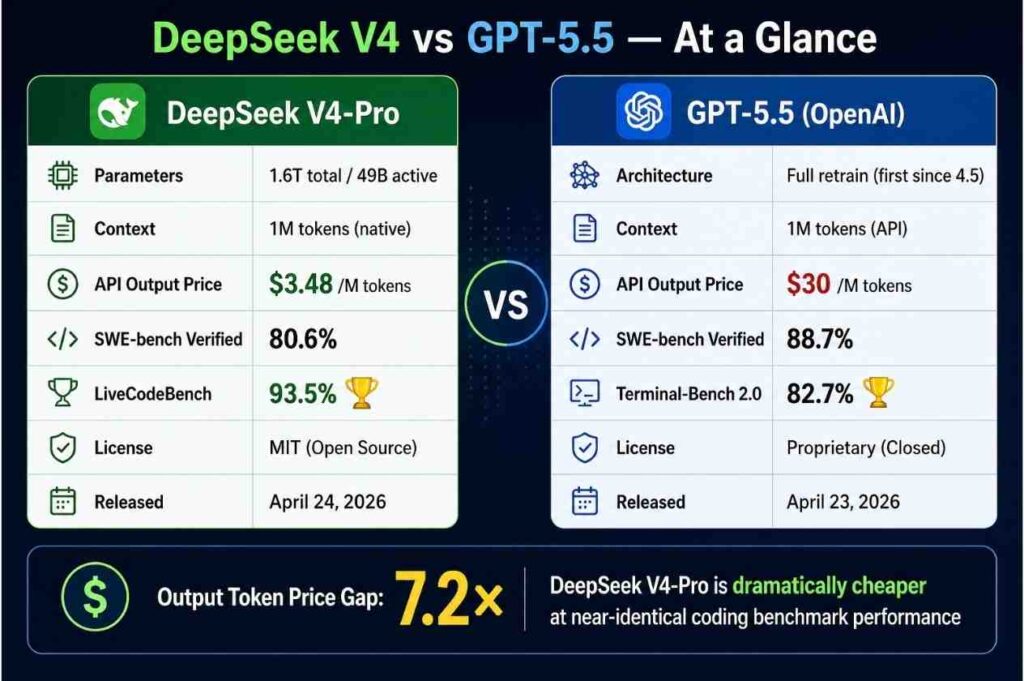
2026년 4월, DeepSeek가 V4를 공개했어요. 1.6조 파라미터에 49B만 활성화되는 MoE 구조, MIT 라이선스, 그리고 출력 1M 토큰 $3.48이라는 가격표. 같은 주 OpenAI는 GPT-5.5를 냈고, 출력은 $30이에요. 9배.
표면적으론 "또 가격 내렸네" 뉴스예요. 하지만 The New Stack의 Janakiram MSV가 짚은 진짜 변화는 가격이 아니라 모양이에요. 예전 LLM 시장은 입문 → 미들 → 프론티어, 가격도 성능도 계단처럼 올라가는 3단 구조였어요. 그런데 봄을 지나며 계단의 가운데 칸이 무너졌어요.
이게 왜 무서운 얘기냐면, 위아래가 둘 다 가운데를 잡아먹고 있어서예요.
- 위 — 프론티어(GPT-5.5, Opus 4.7): 한 번에 복잡한 추론을 끝내고 에이전트 워크플로우를 깔끔하게 돌려요. 대신 비싸요. 1M 출력 $25~$30.
- 아래 — 저가 오픈모델(V4-Flash, V4-Pro): V4-Flash 출력 $0.28, V4-Pro $3.48. 싼데 못 쓸 수준이 아니에요. V4-Pro는 BrowseComp(웹 추론)에서 83.4%로 Opus 4.7(79.3%)을 이겼어요. "싸지만 쓸 만한"이 아니라, 일부 벤치는 프론티어를 넘어요.
- 가운데 — 미들(GPT-5.4 $2.50/$15, Sonnet 4 $3/$15): 가격은 V4-Pro의 4~5배인데 일반 워크로드 성능 차이는 미미해요. "굳이 미들을 쓸 이유"가 빠르게 사라지고 있어요.
그래서 미들에 묶인 빌더는 갈 데가 없어요
Janakiram MSV가 이걸 "AI 미들 클래스의 소멸"이라고 부른 이유가 여기 있어요. 미들 모델에 의존하는 빌더는 가격으로도, 성능으로도 도망갈 곳이 없어요. 위는 비싸서 못 따라가고, 아래는 마진 구조가 아예 다른 게임이거든요.
숫자로 보면 더 분명해요. 같은 작업을 세 티어로 돌렸을 때의 그림이에요.
| 항목 | 프론티어 (GPT-5.5) | 저가 오픈 (V4-Pro) | 사라지는 미들 (GPT-5.4) |
|---|---|---|---|
| 입력 / 출력 가격 (1M) | $5 / $30 | $1.74 / $3.48 | $2.50 / $15 |
| Terminal-Bench (코딩) | 82.7% | 67.9% (Pro-Max) | 약 60%대 |
| SWE-Bench Pro | 58.6% | 55.4% | 50% 미만 |
| BrowseComp (웹 추론) | — | 83.4% | — |
| 라이선스 | 독점 API | MIT (자체 호스팅 가능) | 독점 API |
| 존재 의미 | 최고 난이도 작업 | 90% 일상 워크로드 | 점점 모호 |
벤치 출처는 Artificial Analysis, OpenAI 공식 발표, DeepSeek API Docs예요. 미들 칸의 "존재 의미"가 비어 있다는 게 핵심이에요. 가격으로도 성능으로도 위아래에 다 밀려요.
GPT-5.5 vs V4-Pro
활성 49B (MoE)
Opus 4.7(79.3%) 상회
자체 호스팅 합법
이게 단순 가격 변동이 아니라 구조 재편인 이유가 세 가지예요. 그리고 세 가지 모두 같은 결론으로 수렴해요.
1. 가격-성능 곡선이 U자가 됐어요
예전엔 가격-성능이 거의 직선이었어요. 두 배 비싸면 두 배 좋다는 식. 지금은 가운데가 푹 꺼진 U자예요. 같은 $3 구간에서 V4-Pro와 Sonnet 4가 비슷한 성능을 내는데, V4-Pro는 오픈웨이트라 라우팅·자체 호스팅 자유도가 훨씬 커요. 같은 값이면 더 자유로운 쪽이 이겨요.
2. 오픈웨이트가 "중국 모델이라" 핑계를 없앴어요
V4-Pro는 MIT로 풀려서 Together AI, Fireworks, Hyperbolic 같은 호스팅 사업자가 즉시 서빙했어요. 데이터를 중국 본토로 보내기 싫으면 미국·EU 사업자를 쓰면 그만이에요. "중국 모델이라 못 쓴다"는 도입 거부 사유가 작아진 거예요.
3. 그래서 라우팅이 옵션이 아니라 의무가 됐어요
Augment Code의 2026 가이드는 단도직입적이에요. "단일 모델 베팅은 끝났다." 코딩 에이전트라도 작업 복잡도에 따라 V4-Flash → V4-Pro → GPT-5.5로 분기해야 단가 곡선이 맞아요. 라우팅 안 하면, 한 모델로 모든 걸 다 처리하느라 돈을 태워요.
위·아래가 가운데를 잡아먹는 시장에서, 빌더가 살아남는 길은 "어느 한 칸을 고르기"가 아니라 "칸 사이를 자동으로 오가기"예요.
그럼 뭘 하면 되는데 — 라우팅 4단계
좋은 소식. 라우팅은 거대한 인프라 프로젝트가 아니에요. 첫 도입은 if문 5줄로 충분해요. 작게 시작해서 트래픽이 자라는 만큼 키우면 돼요.
- 워크로드 분류 (1일): 지난 한 달 API 호출을 세 통으로 나눠요 — "단순 분류·요약·번역" / "코드 생성·복잡 추론" / "에이전트 멀티스텝". 비율을 보면 어디에 비싼 모델이 낭비되는지가 바로 보여요. 대개 1번 통(단순)이 호출의 절반 이상인데 거기에 프론티어를 쓰고 있는 경우가 많아요.
- 2단 분기로 시작 (반나절): 단순 작업은
V4-Flash($0.14/$0.28), 복잡 작업은GPT-5.5또는Opus 4.7로. 가운데V4-Pro는 단순이 어려워질 때 fallback으로 둬요. 게이트웨이 없이 그냥 분기 조건문이면 돼요. - 게이트웨이 도입 (1주): 트래픽이 늘면 OpenRouter, Portkey, LiteLLM 중 하나로 옮겨요. SDK 한 줄만 바꾸면 모델 가중치, 비용 한도, 자동 fallback이 다 따라와요.
- 관측·튜닝 루프 (상시): 자기 도메인 데이터 100~300건으로 평가 데이터셋을 만들고 주 1회 회귀 테스트. "정확도 - 비용" 파레토 프론티어 위에서 모델을 빼고 더하면서 라우팅 규칙을 다듬어요.