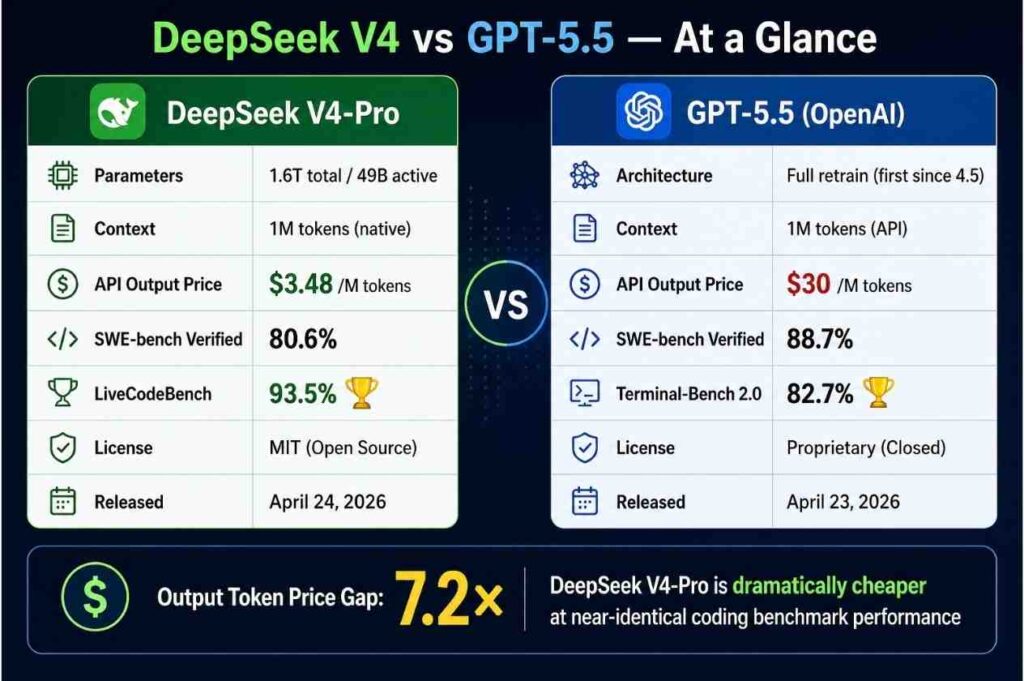
TL;DRDeepSeek V4-Pro shipped at $3.48 per 1M output tokens, leaving GPT-5.5 ($30) nine times more expensive. The mid-tier is collapsing, and builders who survive will route between a frontier model and a cheap open one.
In April 2026, DeepSeek released V4: a 1.6-trillion-parameter MoE with only 49B active, MIT-licensed, output priced at $3.48. The same week, OpenAI launched GPT-5.5 at $30 output.
It looks like another "prices fell again" headline. But Janakiram MSV at The New Stack pointed at the real shift: the entire middle of the market is leaking out.
What is going on
The LLM market used to be a clean three-step staircase: entry, mid, frontier. By spring 2026 the middle step caved in.
At the top sit frontier models like GPT-5.5 and Opus 4.7. Heavy reasoning, multi-step agents, ironclad safety. Output runs $25–$30 per 1M tokens.
At the bottom sit cheap open models: V4-Flash at $0.28 output, V4-Pro at $3.48. V4-Pro hit 83.4% on BrowseComp — beating Opus 4.7 (79.3%). These models are not just "good enough." On some benchmarks they pass frontier models.
The middle? GPT-5.4 ($2.50/$15), Sonnet 4 ($3/$15). Roughly 4–5x V4-Pro's price for marginally better general performance. The reason to use them is fading fast.
Why this is different
Janakiram MSV calls it "the disappearing AI middle class." Builders sitting on mid-tier models have nowhere to go. Up is too expensive, down requires a different business model.
This is not a price tweak. It is structural reshuffling, for three reasons.
| Dimension | Frontier (GPT-5.5) | Cheap Open (V4-Pro) | Vanishing Middle (GPT-5.4) |
|---|---|---|---|
| Input / Output (per 1M) | $5 / $30 | $1.74 / $3.48 | $2.50 / $15 |
| Terminal-Bench (coding) | 82.7% | 67.9% (Pro-Max) | ~60s |
| SWE-Bench Pro | 58.6% | 55.4% | under 50% |
| BrowseComp (web reasoning) | — | 83.4% | — |
| License | Closed API | MIT (self-hostable) | Closed API |
| Reason to exist | Hardest tasks | 90% daily workloads | Increasingly unclear |
Benchmark sources: Artificial Analysis, OpenAI, DeepSeek API Docs.
GPT-5.5 vs V4-Pro
49B active (MoE)
beats Opus 4.7 (79.3%)
self-hosting allowed
1. The price curve became a U-shape
Price-vs-performance used to be near-linear. Pay double, get double. Now the middle of the curve is gouged out. Around the $3 mark V4-Pro and Sonnet 4 are similar in performance, but V4-Pro is open-weight — far more freedom for routing and self-hosting.
2. Routing went from option to obligation
Augment Code's 2026 guide is blunt: "single-model bets are over." Even for coding agents you should branch by task complexity — V4-Flash → V4-Pro → GPT-5.5 — or unit economics break.
3. Open weights changed the game
Because V4-Pro shipped under MIT, hosters like Together AI, Fireworks, and Hyperbolic served it on day one. If you cannot send data to mainland China, route through US/EU hosts. The "Chinese model so we cannot use it" excuse just got smaller.
How to start
Four steps to put a routing layer in place. The first cut is five lines of if-statements.
- Classify your workload (1 day): Bucket the last month of API calls into "simple classify/summarize/translate," "code gen / complex reasoning," and "multi-step agents." The ratio shows where expensive models are wasted.
- Two-way split (half day): Send simple tasks to
V4-Flash($0.14/$0.28) and hard tasks toGPT-5.5orOpus 4.7. Keep V4-Pro as a fallback for "simple turned out hard." - Adopt a gateway (1 week): When traffic grows, move to OpenRouter, Portkey, or LiteLLM. One SDK swap gives you weights, cost caps, and auto-fallback.
- Observe and tune: Build a 100–300 sample eval set per model, run weekly regressions, and keep models on the "accuracy vs cost" Pareto frontier.
Go deeper
The New Stack — the middle-class collapse Janakiram MSV decomposes the market into three tiers and lays out a builder response. thenewstack.io
DeepSeek V4 release notes Pro/Flash pricing, MoE architecture, context length, license. Primary source for routing design. api-docs.deepseek.com
Artificial Analysis V4 benchmarks Independent results across Terminal-Bench, SWE-Bench, BrowseComp. artificialanalysis.ai
Augment Code — 2026 coding-model routing guide Maps task complexity to model with code samples. augmentcode.com
VentureBeat — V4 at 1/6 the cost Same-performance cost analysis, hosting partner moves, enterprise adoption signals. venturebeat.com


